Case Study: Wired Informatics trains a word-sense disambiguation model on open weights that keeps sensitive data safe
With Oumi, a healthcare AI team moved from 84.5% to 88.9% concept-validity precision on messy medical text — without sending a single patient record to a third-party API
By Stefan Webb
May 15, 2026

Problem
Clinical text is one of the hardest substrates for general-purpose language models. Real-world medical documents arrive as templated forms, scanned PDFs, and OCR’d notes — laced with checklists, billing codes, scoring-tool names, family-history mentions, prophylaxis context, and noisy text fragments.
For Wired Informatics, the engineering bar was sharp: every mention of a medical term had to be classified across three structured fields simultaneously. First, is this a valid medical concept, or just OCR noise, a template label, or an administrative artifact (concept validity)? Second, what clinical category does it belong to — disease, sign/symptom, procedure, vital sign, measuring unit, or non-clinical context (validity classification)? Third, does it apply to the patient’s actual health, or is it negated, hypothetical, a family-history mention, prophylaxis, or part of a screening tool?
Off-the-shelf LLMs failed in predictable ways: hallucinating concepts from OCR garbage, treating template headers as patient findings, missing negation cues, and confusing scale names like “Glasgow Coma Scale” for the disorder itself. On Wired Informatics’s held-out validation set, the base model got the validity question wrong on roughly one in six rows — an error rate their clinical workflows could not tolerate.
Solution
Wired Informatics used Oumi to build a tight, evaluation-driven iteration loop that converted aggregate accuracy numbers into an actionable taxonomy of what to fix next.
“Oumi enabled us to rapidly develop a specialized model for clinical text that delivers high-precision word sense disambiguation — something general-purpose LLMs struggle to achieve. Its modular framework allowed us to move quickly from problem identification to deployment, while integrating seamlessly into our clinical workflows.” — Murali Minnah, Strategy Officer, Wired Informatics
An automated quality-review system across six criteria. : Rather than chasing a single aggregate metric, the team defined six independent judges — each checking a different combination of the three target fields — using Qwen 3.5 (397B) as the strong evaluator model. This let them isolate which sub-skill regressed when scaling the dataset, rather than guessing at the cause.
Failure-mode analysis on every iteration: After each evaluation, Oumi surfaced the dominant error categories — OCR Noise Misidentification, Template Misclassified as Patient-Specific, Tool vs Disorder Confusion — turning a pass-rate number into a roadmap for the next iteration.
Targeted data generation (synthesis) instead of brute force: Instead of blindly adding more data, Wired Informatics generated corrective examples aimed at the specific failure modes the analysis surfaced. Training and evaluation datasets were versioned so each iteration was cleanly tied to a specific data state.
Open-weight base model, deployed in the customer’s own environment: Starting with Qwen3-4B, the team scaled to openai/gpt-oss-20b for the production model — keeping everything deployable inside their clinical infrastructure under LoRA SFT, with no reliance on closed external APIs.
Outcome
The fine-tuned openai/gpt-oss-20b model, trained on approximately 30,000 examples, was evaluated against the base model on a held-out validation set under the same six-judge suite. The final model was self-hosted inside clinical infrastructure; there was no closed-API dependency or vendor lock-in and sensitive data remained on-premise.
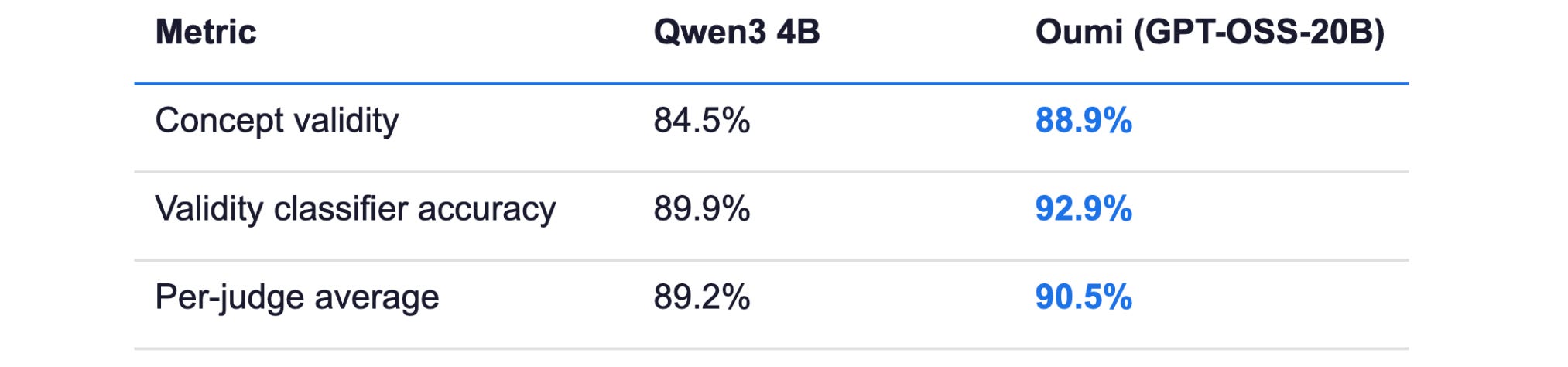
Beyond the headline metrics, the durable win was the workflow itself. The same train → evaluate → analyze → synthesize loop that produced the word sense disambiguation model can be re-pointed at the next clinical NLP problem — same dataset framework, same judge-design pattern, same deployment surface.
What this means for compliance, security, and legal
PHI never leaves the environment. The model is self-hosted. No inference traffic to an external API, no BAA dependency on a model vendor, no third-party data processor in the path.
Auditable from data to weights. Training datasets are versioned, evaluation criteria are explicit and reproducible, and the model weights belong to the customer. A regulator asking “how does this system make decisions, and how do you know it still works” has answers.
No vendor lock-in on the runtime. The model is built on openly licensed weights and a published training recipe. If the vendor relationship ever changes, the deployed system keeps running.
The workflow is portable. The same train → evaluate → analyze → synthesize loop applies to the next clinical NLP problem — and to problems in adjacent regulated domains.
What’s next
Wired Informatics’s modular approach is designed to scale horizontally across clinical NLP problems.
The same framework that produced gains in concept validity and clinical categorization can be applied to adjacent challenges: negation detection, family-history classification, procedure coding, and structured extraction from insurance claims or discharge summaries.
This approach travels well wherever source documents are messy and structured outputs are mandatory: insurance claims adjudication, legal and contract analytics, financial document extraction, industrial QA reporting, and government filing extraction all share the same problem shape.