DCVLR Competition Results: Data Curation for Vision-Language Reasoning
By Oussama ELACHQAR
October 31, 2025
We are excited to present the results of the inaugural DCVLR (Data Curation for Vision-Language Reasoning) competition at NeurIPS 2025!
DCVLR is an open-source initiative to advance data curation methodologies for vision-language models. The competition is a collaboration led by Oumi.ai and Lambda.ai, with community contributions from researchers at Stanford, MIT, NYU, UW, Caltech, AI2, University of Tuebingen, Tel Aviv University, and other institutions.
This first edition brought together researchers from around the world to investigate how data curation strategies affect vision-language model performance on complex reasoning tasks.
Competition Design
Recent research (LIMA, LIMO) has shown that careful curation of small datasets can substantially improve task performance. However, many datasets and data generation strategies remain proprietary even when model weights are publicly released. DCVLR emphasizes reproducible and scalable data curation methods.
Participants were asked to:
Curate training datasets of approximately 10,000 examples
Fine-tune vision-language models (Qwen2.5-VL-7B, Molmo, or InternVL3)
Optimize performance across a comprehensive evaluation suite
Curation strategies could build upon existing methodologies or develop new approaches, with emphasis on reproducibility and scalability.
Final Evaluation Suite
Models were evaluated across 10 benchmarks spanning mathematical reasoning, scientific comprehension, and spatial understanding:
VMCBench_DEV - Visual mathematical comprehension
LiveXivTQA - Academic paper text understanding
OlympiadBench - Competition-level mathematics
Omni3DBench - 3D spatial reasoning
Physics domains: atomic_dataset, electro_dataset, optics_dataset, quantum_dataset, statistics_dataset, mechanics_dataset
Results
Participation
The competition attracted international interest from both academic and industry researchers:
59 unique teams registered with approximately 196 total participants
Teams from 42 different organizations, as well as several independent researchers
18 academic institutions (43% of organizations)
23 companies (55% of organizations)
Leaderboard
Evaluation was conducted using best submission per team across 10 benchmarks). The baseline model was Qwen2.5-VL-7B-Instruct with an accuracy of 38.83%.
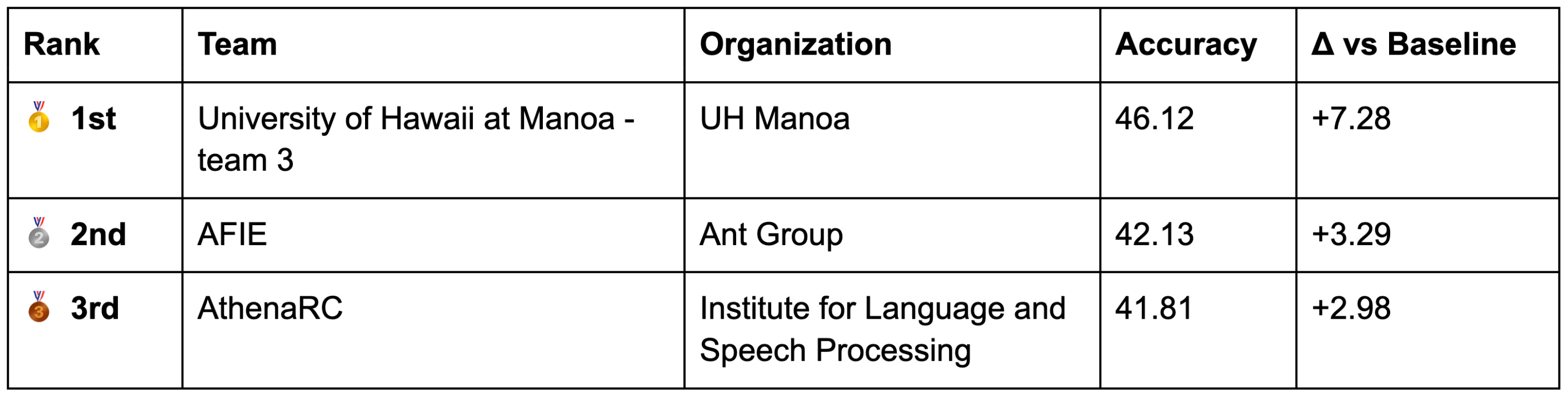
The full leaderboard with all team submissions is available on the competition website.
The competition’s emphasis on reproducibility and open methodology enabled participation from diverse research groups across academic institutions and industry. The infrastructure and methodologies developed for this competition are publicly available to support continued research in data-centric approaches to vision-language model development.
The results also reveal areas for future work: developing curation strategies that maintain performance across diverse reasoning domains, understanding the mechanisms underlying task-specific transfer patterns, and scaling these approaches to larger datasets and model architectures.
Conclusion
We extend our appreciation to all participating teams for their contributions to advancing our understanding of data curation for vision-language reasoning. The approaches developed and insights gained through this competition provide a foundation for continued research in data-centric methods for improving vision-language model capabilities.
We encourage the research community to build upon these results and explore new directions in data curation strategies for vision-language models.
Community Resources
The competition infrastructure will remain open-source:
Competition Code: github.com/oumi-ai/dcvlr-internal
Oumi Framework: github.com/oumi-ai/oumi
Data-Preproc: github.com/oumi-ai/data-preproc
VLMEvalKit Fork: github.com/oumi-ai/VLMEvalKit
Documentation: oumi.ai/docs
Future Competitions
Based on community interest and lessons learned, we plan to keep accepting submissions for the DCVLR competition. More details about the submission process will be provided after the workshop at NeurIPS 2025.
Resources
Additional information and resources are available through the following channels:
Competition Website: dcvlr-neurips.github.io
Updates: Sign up for notifications
Competition Repository: github.com/oumi-ai/dcvlr-internal
Oumi Documentation: oumi.ai/docs
Community Discussion: Discord server for technical discussions
Acknowledgments
We acknowledge the contributions of the following individuals and organizations:
Sponsors
Lambda Labs for providing GPU credits to participants, enabling teams without extensive compute resources to compete
NeurIPS 2025 for hosting and supporting the competition
Participating Teams
We acknowledge all 59 registered teams and all the participants who engaged with the competition.
These teams’ contributions have advanced our understanding of data curation for vision-language reasoning.
Organizing Committee
Benjamin Feuer, Rohun Tripathi, Oussama Elachqar, Yuhui Zhang, Neha Hulkund, Thao Nguyen, Nimrod Shabtay, Vishaal Udandarao, Xiaohan Wang, Stefan Webb, Emmanouil Koukoumidis, Ludwig Schmidt, Saining Xie, Serena Yeung-Levy, Paul Liang, Sara Beery, and Georgia Gkioxari
Infrastructure Partners
Oumi.ai for developing the training and evaluation infrastructure
Lambda.ai for compute support and partnership
Citation
If you reference the DCVLR competition in your work, please cite:
@misc{dcvlr2025,
author = {Feuer, Benjamin and Tripathi, Rohun and Elachqar, Oussama
and Zhang, Yuhui and Hulkund, Neha and Nguyen, Thao and
Shabtay, Nimrod and Udandarao, Vishaal and Wang, Xiaohan and
Webb, Stefan and Koukoumidis, Emmanouil and Schmidt, Ludwig
and Xie, Saining and Yeung-Levy, Serena and Liang, Paul and
Beery, Sara and Gkioxari, Georgia},
title = {{DCVLR: Data Curation for Vision-Language Reasoning}},
year = {2025},
month = {June}
howpublished = {NeurIPS 2025 Competition},
url = {https://dcvlr-neurips.github.io}
}