How much money are you throwing away on Anthropic and OpenAI models?
Specialized AI can be 10x-100x fold or more cheaper than a general-purpose frontier model with the same or better performance. Learn how much you could save by moving from Anthropic to specialized AI
By Stefan Webb
May 19, 2026
Across America, the AI coffers are running dry. Uber’s CTO Praveen Neppalli Naga recently announced that the company had already exhausted its entire $3.4 billion research and development budget for 2026—and this at a time when frontier-model providers are raising costs on AI consumers. Next month, programmatic use of Claude—for agents, for example—will be separated from chat usage and charged by consumption rather than as part of a fixed-cost subscription, a change estimated to double the cost of Claude for that class of users. In many cases, it is already more expensive to build products with AI coding agents than with human labor. “For my team, the cost of compute is far beyond the costs of the employees,” Bryan Catanzaro, vice president of applied deep learning at Nvidia, recently told Axios.
As the cost of compute rises, it becomes ever more pertinent to reconsider how we build with AI and how we can do more with less. In our recent post, “Building Customer Support with a sub-1B Small Language Model that Beats GPT-5.4”, we established that fine-tuned SLMs can greatly outperform frontier LLMs like GPT-5.4 and Opus 4.6 on specific tasks—our 0.8B custom SLM beat GPT-5.4 by 6.3% in accuracy on triaging customer support queries. But what about the cost? SLMs are drastically more economical to run in production, with dollar savings typically between 90% and 99%.
In this post, we’ll explain how to realistically calculate the costs of both API-based and self-hosted model inference going into some depth about the different considerations and assumptions made. Then we’ll vibe-code a script to calculate and compare the costs for the customer support task of our previous post, examining the effect of varying our assumptions.
By the end, you’ll be able to:
Make an informed choice on whether to adopt custom AI based on the cost savings if you do so;
Understand the cost/model size/performance tradeoff between different SLMs to decide on the right one;
Appreciate the limitations of cost-estimation and the factors that need to be considered in your specific scenario.
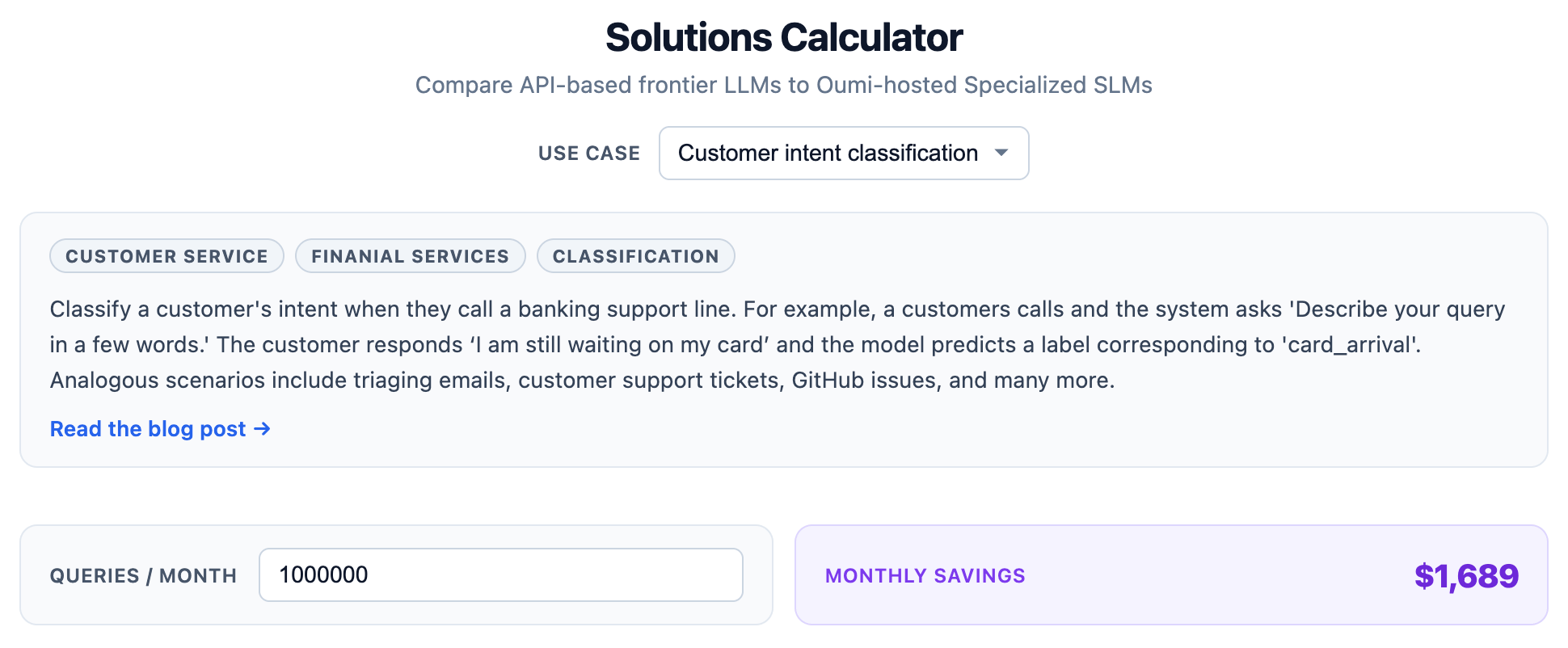
We’re providing a dedicated “solutions cost calculator” on our website (coming soon) so you can compare costs between general-purpose models and various self-hosted fine-tuned models on your specific task. In the meanwhile, please find a preliminary version of the calculator, illustrated above, at this link.
Discussion
Calculating the relative cost of self-hosted custom AI to API-based frontier models is not a straightforward task. The two main challenges are:
It requires us to compare inference priced per-token with inference priced per-machine-hour
The calculations vary greatly depending on the exact task, hardware, inference engine, and other factors.
Let’s examine this in more detail.
Scope
In this article, we’re restricting our discussion to large language models (LLMs) based on decoder-only transformer architectures and not any general neural network or other Machine Learning model. Examples of decoder-only LLMs are GPT-5.4, Claude Opus 4.6, Qwen3.5, GPT-OSS, Kimi-K2.6, DeepSeek-V3.2, to name just a few. Other types of AI models, such as vector embedding models, would require a different method and assumptions.
Application matters
Cost will vary depending on the specific application. This is because different applications can require very different volumes of tokens, as well as different ratios of input to output tokens. Tasks requiring long outputs will drive up costs more rapidly for models behind an API, because providers charge higher rates for output tokens (model responses) than input tokens (prompts)
The ratio of input to output tokens may vary greatly across applications. For a classifier, the output could be one or a few tokens for the predicted class (“accept”, “reject”, “unknown”). For information extraction, the output could be several hundred tokens for the JSON structure containing the fields extracted from the input. Models employing reasoning greatly increase the number of output tokens.
Another consideration related to how the application affects the cost is that it is more intuitive to report cost in terms of 1000s of queries and for this we need to know the average number of tokens per query, which is highly dependent on the task. A customer support classifier is likely to have a small number of input and output tokens—a spoken sentence or two plus a single label—relative to an information extraction model that inputs entire documents and outputs large JSON structures.
A realistic calculation requires empirical measurements
It is challenging to obtain estimates of token per second for every combination of model, hardware, and inference engine. In reported benchmarks, inference throughput is typically reported for decoding and not prefill, or else it makes a strict assumption about the ratio of input to output tokens, which varies greatly across tasks. To make a realistic calculation, we should measure inference speed on a small handful of typical hardware and inference engine combinations for the specific task under consideration.
We need to make assumptions
Despite our intention to obtain empirical measurements of the task-specific self-hosted inference throughout, we must make a number of assumptions. Making assumptions is fine provided they are reasonable and are made explicit.
For API-based inference:
The context window is “short” where it affects API-based pricing
The pricing effects of caching are ignored.
Token counts do not vary drastically across different model’s tokenizers for a given input
For self-hosted or managed inference:
Inference is run at FP16 or BF16 precision
Web traffic and storage costs are negligible
We can prorate the fraction of each machine-hour the GPU is being utilized, for instance, because we are using the same GPU for other models for complete utilization.
We use a batch size of 1
We are not using optimizations like continuous batching
For both:
The costs of engineering time and model training are negligible, an assumption made realistic by the Oumi Agent.
An example: calculating the cost of triaging customer support queries
Let’s work through the method proposed above for the customer support triage model we trained in our recent post, “Building Customer Support with a sub-1B Small Language Model that Beats GPT-5.4”. If you’ll recall, we fine-tuned Qwen3.5 0.8B on the banking77 dataset using the Oumi Platform and were able to out-perform GPT-5.4 by 6.3% and Opus 4.6 by 8.4%. in accuracy. We have similarly fine-tuned Qwen3.5 2B, 4B, and 9B so that we can examine the trade-off between cost, model size, and performance for SLMs.
We’ll assume the hardware is a single Nvidia H100 card, the inference engine is the latest version of vLLM, and the cloud provider is Lambda.
Measuring self-hosted inference speed
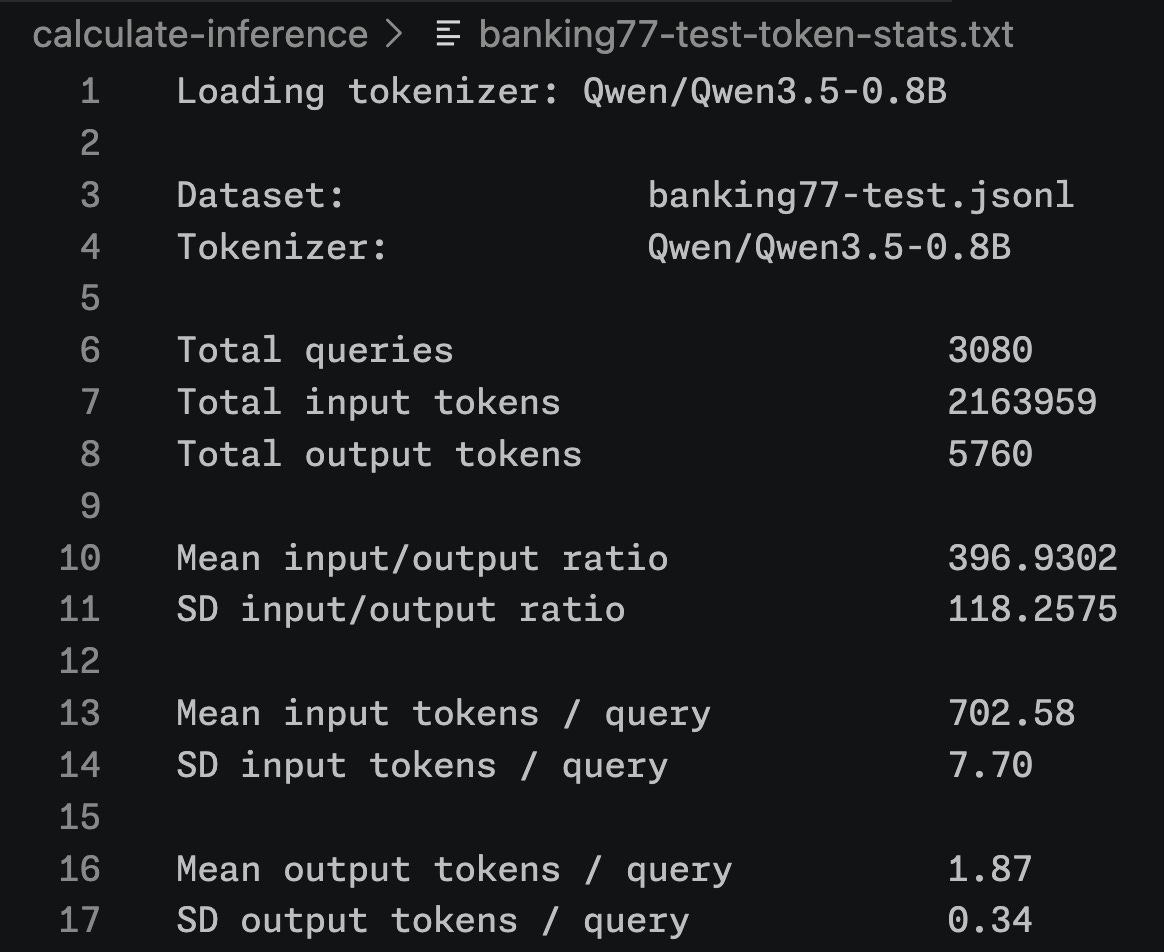
Locally, we tokenize the banking77 dataset with Qwen’s tokenizer and record the total number of tokens, ratio of input to output, and the mean and standard deviation length of a single input or output:
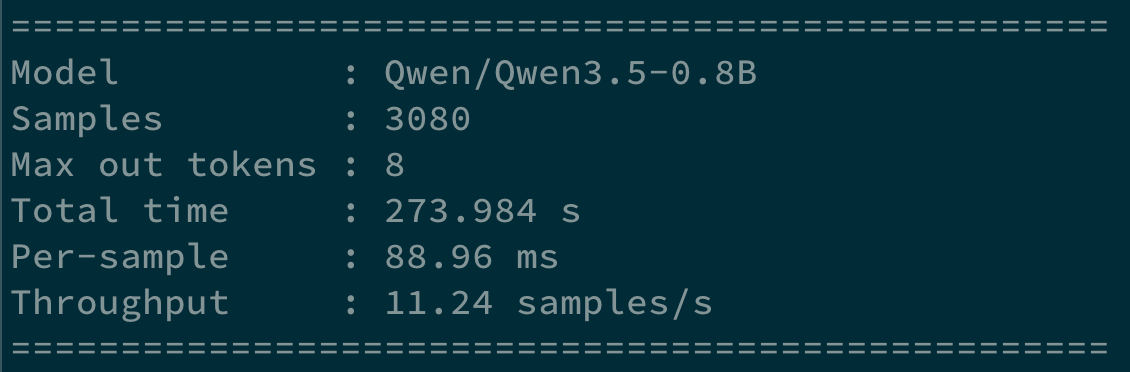
Separately, we launch a remote instance, and time inference over the test dataset, restricting the number of output tokens sampled in case the model does not respect the output format of a single label (see the blog post).
Results
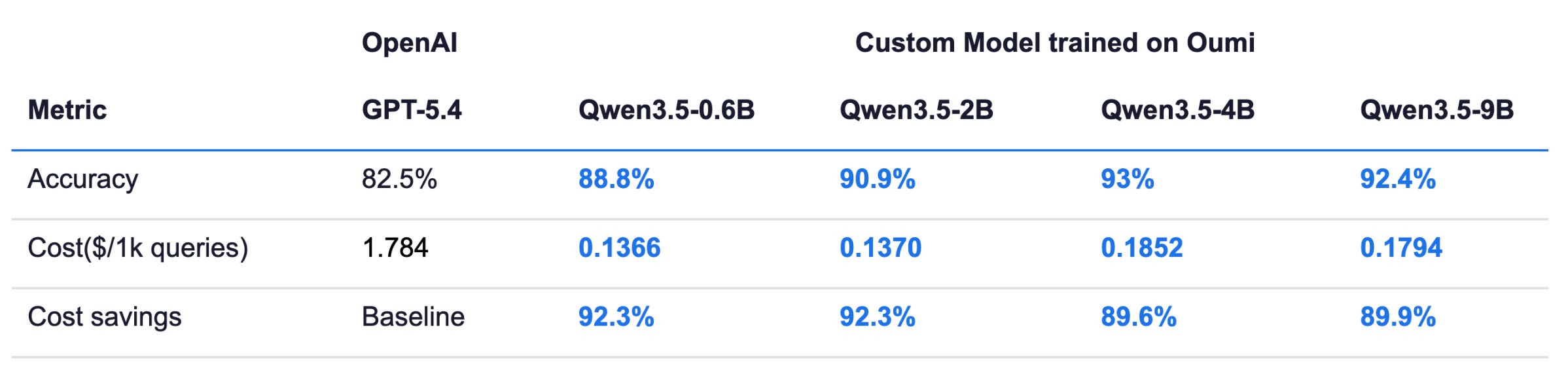
Using our inference-cost calculator and the empirical values from above, we can calculate the cost savings from, for example, using Oumi for managed inference. The results are in the table above for a range of fine-tuned model sizes, along with the primary metric, so we can not only assess savings relative to a frontier model but the tradeoff in performance and cost.
It is interesting to note that inference throughput and performance metrics do not necessarily scale linearly in the model size. From our measurements, accuracy and throughput for the 0.6B and 2B models are similar, and likewise the 4B and 9B models. The 4B model achieves a good tradeoff between accuracy and cost savings. A more linear relationship between model size and accuracy could possibly be achieved by more detailed hyperparameter tuning, which we leave for future work.
Irrespective of the SLM used for fine-tuning, the custom model trained on Oumi’s platform achieves about a 10x cost reduction while improving accuracy by up to 10%. There does not seem to be a good reason to use a general-purpose model for this task.
Summary
We have shown how to realistically estimate and compare costs between API providers (usage-based) and self-hosted or managed inference (time-based). Our assumptions have been conservative: additional steps like quantizing or pruning your model, applying continuous batching, and exploiting caching would reduce costs even further.
For our example of a customer service model for triage, you can achieve a cost savings of X% per 1000 queries using managed inference instead of throwing away money to general-purpose model providers like Anthropic and OpenAI. And with some reasonable assumptions on how much traffic
While lower inference cost is a prime benefit of self-hosted and managed inference, let’s not forget about the others:
Lower latency
Higher performance metrics (for fine-tuned models like our customer service model)
Full data sovereignty
Avoiding vendor lock-in
We plan to develop the methods here into a webpage where you can estimate costs for specific applications presented in Oumi’s tutorials across open-weight models and inference providers, as well as comparing to Oumi’s managed inference where we take care of the infrastructure for you. View a preliminary version of the cost calculator here.
In the meanwhile, why not try out Oumi’s new managed inference feature? Deploying your model to production is as simple as a button click. No hassles of downloading your model, uploading to the cloud, setting up a cloud instance, testing everything, and continuing to manage and monitor GPU infrastructure. Oumi makes the productionization of specialized AI models a breeze!
Find out more by logging in to the platform and clicking the new “Deploy Model” button in the Models tab:
Resources
Further reading
Anthropic Flexes Pricing Power as Its Customers Willingly Eat the Cost — The Information
Anthropic Changes Pricing to Bill Firms Based on AI Use as Demand Jumps — The Information