Newsletter: Stop throwing money away on frontier AI (and other news)
Updates for Week of May 18, 2026
By Stefan Webb
May 19, 2026
💸 Last month, Uber’s CTO announced the company had already burned through its entire $3.4B 2026 R&D budget. Programmatic Claude usage is about to roughly double in price when it splits from chat subscriptions next month. Nvidia’s VP of applied deep learning recently told Axios that, for his team, the cost of compute is now far beyond the cost of the employees.
The economics of building on rented frontier intelligence are unraveling, and this week’s newsletter is a three-part argument for what comes next.
We’ll show you exactly how much money you’re leaving on the table by defaulting to GPT-5.4 or Opus 4.6 for tasks a sub-1B specialized model can handle better. We’ll introduce a real customer, Kaizen Gaming, that replaced Kimi-K2 in production with a 3B fine-tune and never looked back. And we’ll discuss the latest open-source tooling Oumi OSS v0.8 that makes the whole loop from training to deployed endpoint a single command away.
This week’s deep dive
How much money are you throwing away on Anthropic and OpenAI?
In our latest analysis, How much money are you throwing away on Anthropic and OpenAI models?, we walk through how to realistically calculate the cost difference between API-priced frontier models and self-hosted SLMs, accounting for hardware, inference engine, input/output token ratios, and task-specific throughput. The headline result on our customer-support triage benchmark: a fine-tuned Qwen3.5 SLM delivers roughly a 10x cost reduction while improving accuracy by up to 10% over GPT-5.4. That’s before quantization, continuous batching, or prompt caching, all of which would push the savings further.
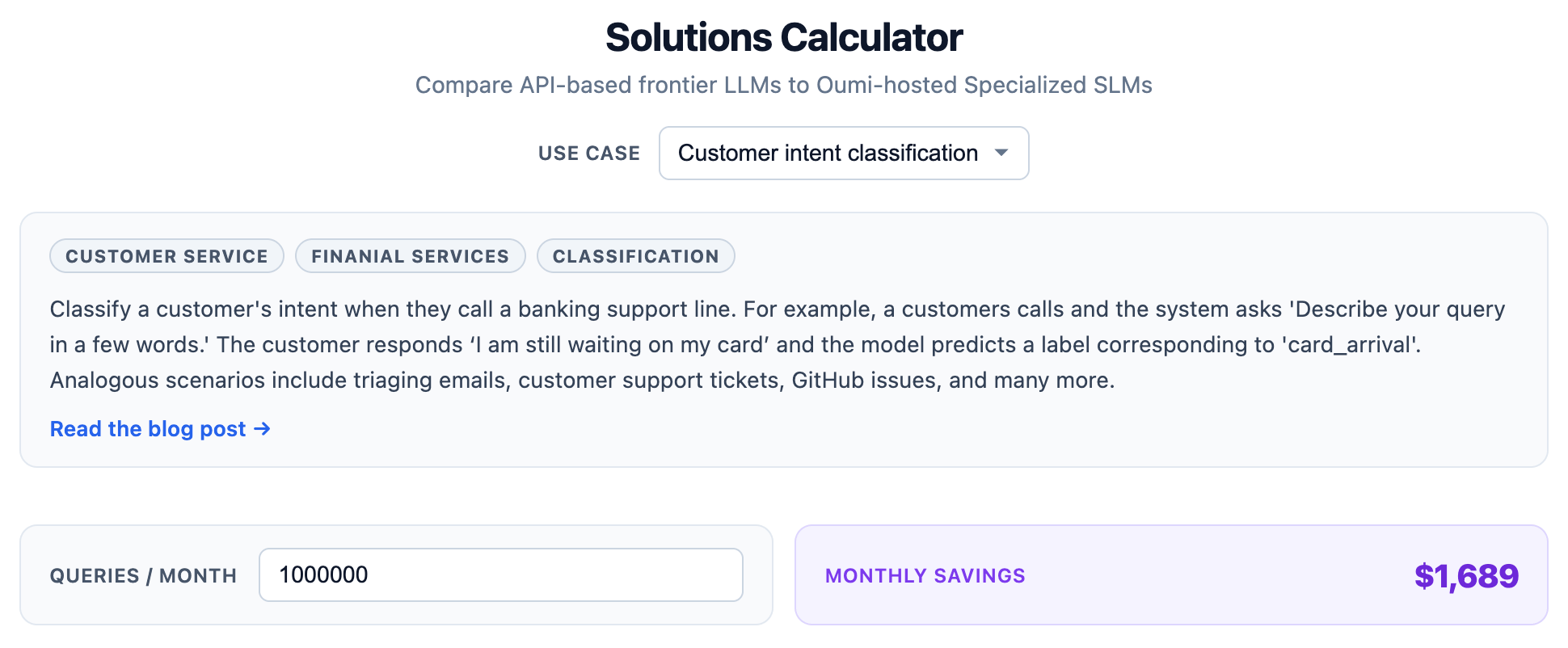
The post also unpacks the trade-off between model size, throughput, and accuracy across 0.8B, 2B, 4B, and 9B fine-tunes. Interestingly, the curves aren’t linear, the 4B hits the sweet spot for this task. We’ve also released a preliminary cost calculator so you can plug in your own task assumptions and see what you’d save. A full version is coming soon to oumi.ai.
Customer Story
Kaizen Gaming builds a 3B text-to-SQL model that beats Kimi-K2
Kaizen Gaming operates sports betting and online gaming products at scale across European and Latin American markets. Their internal analytics platform turns natural-language questions into SQL but only against an allow-listed view layer, with mandatory business filters, canonical entity IDs, and a required output wrapper. Prompting a frontier model with the rules in the system prompt failed in two structural ways: occasional rule drift (a small failure rate at query volume becomes a large failure count), and a 70B-class hosted model is expensive to call on every analytics question.

Using Oumi’s declarative synthesis recipes, the Kaizen team generated ~500 schema-grounded training samples, including paraphrased hard negatives, and fine-tuned Qwen2.5-3B-Instruct with LoRA. They evaluated it against Qwen2.5-72B, Qwen3-235B-A22B, and Kimi-K2 using three task-specific judges — Instruction Compliance Strict, SQL Hygiene, and Topic Adherence — instead of one generic one. The 3B fine-tune matched or exceeded all of them on Kaizen’s task, hit a perfect 1.00 on SQL Hygiene after the hard-negatives iteration, and now ships in production at a fraction of the cost and latency. Full story via the link.
“Oumi’s synthesis recipes took us from schema to 500 training samples in just a few iterations. Controlling data distribution was simple, and evolving from basic to complex queries required only small config changes. The declarative, version-controlled approach enabled rapid iteration and a production-ready model, without manual data creation.” — Ioanna Sanida, Data Science Team Lead, Kaizen Gaming
What’s new in Oumi OSS
Oumi OSS v0.8: Deploy, MCP, and Batch Inference Everywhere

Oumi OSS v0.8 is out, and it closes the loop from training to production. Highlights:
oumi deploy— A single command takes a fine-tuned checkpoint to a live, autoscaling, dedicated endpoint. Validates the model, uploads weights, stands up the endpoint, polls until live, and (optionally) fires test prompts. Fireworks.ai and Parasail ship as providers in this release, with more on the way.oumi-mcpserver — Drop Oumi inside Claude Desktop, Claude Code, Cursor, or any MCP-capable assistant. The server exposes ~500 bundled YAML configs, pre-flight validation, and the ability to launch and monitor training, eval, and inference jobs — local or cloud — directly from chat.Batch inference across hosted providers — Anthropic, Fireworks, and Together now share a unified batch API in Oumi, with one
infer_batch()call handling the full submit-poll-fetch lifecycle and ~50% cost savings on offline eval and synthetic data jobs.Built-in RPM/TPM rate limiting — Every
RemoteInferenceEnginenow does sliding-window rate limiting natively, tracking requests-per-minute and input/output tokens-per-minute independently. No more debugging 429s mid-eval.Plus: Cerebras inference engine, multi-turn conversation synthesis, Transformers v5, and new recipes for Qwen3.5 0.8B, Qwen3-VL (2B–30B), Qwen3 MoE, GPT-OSS 120B LoRA, and a Llama 4 Scout refresh.
Install with pip install oumi (or pip install "oumi[mcp]" for the MCP server). Full changelog and quickstart guides in the release post.
Until next time
Three pieces, one argument: specialized intelligence is cheaper, more accurate, and now, with oumi deploy on Oumi OSS and Managed Inference on the Oumi Platform, just as easy to ship. If you’ve been waiting for the right moment to move a production workload off a frontier API, this week is a good one to try.
As always, we’d love your feedback. Drop us a line, join our Discord, or just hit reply.
Happy Building and May the Vibes be With You! ✨