Build Custom Evaluations for any Open or Closed Model in just 50 Lines of Code
Build custom LLM evaluations in 50 lines of code — comparing GPT-4o, Claude 3.7, LLaMA 405B, and Gemini as hallucination classifiers
By Stefan Webb
September 14, 2025
The Evolving Landscape of LLM Evaluations
As the AI field advances at breakneck speed, the methods for evaluating new models are struggling to keep up. Over the past year alone, thousands of new evaluation benchmarks have been introduced, each designed to tackle an array of diverse and complex scenarios. However, these benchmarks often lose relevance almost as quickly as they’re released, especially with each new generation of models. There are two primary reasons why this happens.
First, every time a state-of-the-art (SOTA) model is released, it typically delivers a significant leap in reasoning and performance capabilities. This often pushes the boundaries of existing benchmarks, rendering them outdated or "saturated", a phenomenon that occurs when a benchmark no longer provides a meaningful challenge. When models can easily meet or exceed the benchmark's goals, they no longer serve as an effective measure of progress.
Second, data contamination has emerged as a growing challenge. Over time, benchmarks become vulnerable to the very models they are designed to assess. Whether intentionally or unintentionally, data from benchmarks (or highly correlated derivatives) finds its way into the training datasets of new models, undermining the integrity of performance evaluations. This contamination distorts the results, making it increasingly difficult to trust benchmarks that have been in use for a while.
In addition to the rapid obsolescence of LLM benchmarks, most existing benchmarks are optimized for broad, standardized tasks, often failing to align to the specialized needs of enterprises. Enterprises require a more tailored approach, enabling them to evaluate LLMs against custom benchmarks that reflect their unique industry-specific requirements, use cases, and data. Furthermore, many enterprises are legally restricted from sharing sensitive data with third-party platforms, leaving them unable to fully assess models' suitability for their specific needs. This highlights the importance of enabling custom in-house evaluations, allowing businesses to quickly create, iterate, and test with their own meaningful benchmarks.
Custom Oumi Evaluations
In response to the growing demand for customized evaluations and the pressure to benchmark models at an accelerated pace, evaluation platforms must evolve. They need to enable users to iterate quickly and seamlessly integrate new generations of benchmarks. At Oumi, we are committed to addressing these challenges with three core features, designed to better serve our community. First, we’ve made it incredibly easy to implement custom evaluations. Second, we ensure that every evaluation is fully recordable and reproducible. Finally, we allow users to seamlessly evaluate most open and closed models with a simple configuration change - no code changes are required.
• Incredibly Easy to Implement. You can now build a custom evaluation from scratch with fewer than 50 lines of code to easily evaluate any generative model. All you need is your data (a list of prompts to query the model), a short function to assess the model responses, and a simple config file to select the model you wish to evaluate. In this post, we demonstrate how to assess any generative model as a hallucination classifier with minimal code: just 15 lines for the evaluation function and 20 lines for the configuration file.
• Consistent & Reproducible. We understand the frustration of trying to remember the exact configurations and hyperparameters used in previous evaluations. That’s why we log everything automatically, ensuring you can easily repeat the same evaluation with the same settings—and get the exact same results every time.
• Open & Closed Model Support. Thanks to Oumi’s broad set of prebuilt inference engines, most open models (LLaMA, DeepSeek, Qwen, Phi and more), closed models (Gemini, Claude, OpenAI) and Clouds (Vertex, Together, SambaNova, and more) can be evaluated using the same unified API. You only need to adjust a few values (e.g., model name, API key) in the configuration file, with no code changes required. We have invested in the robustness of each inference engine by leveraging multiple workers, politeness policies, and fault-tolerant mechanisms, so that you can rely on seamless, high-quality evaluations with high performance and reliability.
To build your own custom evaluations, get started by reviewing the Build your own Custom Evaluation notebook.
Evaluation Use Case: LLM Hallucinations
A common use case for Large Language Models (LLMs) is document comprehension — whether through analysis, summarization, or open-book Q&A based on its content. However, a major challenge is the models’ propensity to hallucinate. Although the document is meant to serve as the premise (or ground truth) for generating accurate and relevant responses, LLMs often generate content that seems plausible but is, in reality, entirely fabricated. This undermines trust in LLMs, particularly in mission-critical applications, often preventing enterprises from deploying them to production.
To trust LLMs, it is critical to detect and mitigate hallucinations. Detection involves employing a hallucination classifier to determine whether a given hypothesis (i.e., a response generated by an LLM) is entailed from the premise (i.e., the reference document, which serves as the “ground truth”). We conducted a case study, evaluating several SOTA LLMs (GPT-4o, Claude 3.7, LLaMA 405B, and Gemini Pro 1.5) as hallucination classifiers and measured the accuracy of their classifications. To carry out this evaluation, we leveraged the Adversarial Natural Language Inference (ANLI) dataset, which offers a rich collection of premises and hypotheses.
You can find a detailed notebook for this case study here.
Case Study: Evaluating LLMs as Hallucination Classifiers
Experimental Results
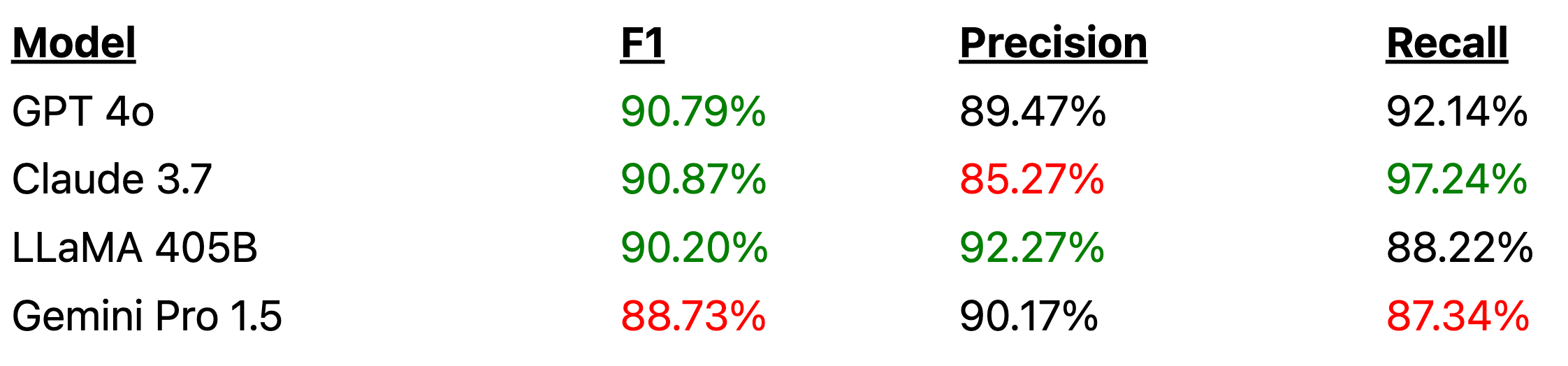
The table below presents the performance of the models we evaluated. Our first observation is that GPT-4o, Claude 3.7, LLaMA 405B show similar performance, while Gemini Pro 1.5 scores roughly 1.5 point lower. However, a deeper look reveals that Claude 3.7 actually strongly outperforms the other models. As data scientists know well, raw metrics can be misleading; read on for a more detailed analysis!
Findings
• Finding 1: Claude 3.7 is the top performer. Although the overall performance (F1 score) of all models is quite similar, we noted that Claude 3.7 has significantly lower precision compared to other models. This suggests that Claude tends to classify as hallucinations hypotheses that are annotated in the ground truth as supported. However, upon reviewing numerous allegedly supported hypotheses that were flagged as hallucinations by the model (false positives), we found that most of these were indeed hallucinations. The ANLI dataset was annotated in 2020, when both the quality of annotations and the reasoning abilities of models were much lower. As a result, some subtle cases were mislabelled. Our analysis concluded that Claude 3.7 is actually better at detecting hallucinations than models with human-in-the-loop from five years ago.
• Finding 2: Gemini Pro 1.5 lacks nuanced reasoning. Among all models, Gemini performed the weakest, particularly in terms of recall. This indicates that it struggled more than other models in correctly identifying actual hallucinations. After reviewing a large number of false negatives (hallucinations predicted as supported), we found that Gemini has the tendency to label plausible-sounding statements as supported by the premise, even when they are not. The lack of nuance in its reasoning process stems from its tendency to rely heavily on general world knowledge, without sufficiently evaluating small but critical details of the premise. Once a hypothesis seems reasonable, Gemini tends to stop reasoning, failing to probe deeper or account for edge cases. As a result, it becomes a less reliable classifier, particularly in high-stakes fields like law, finance, or medicine. For instance, Gemini incorrectly claims that a stock is a blue-chip investment simply because the company, which was on the verge of filing for bankruptcy protection, managed to recover some of its losses.
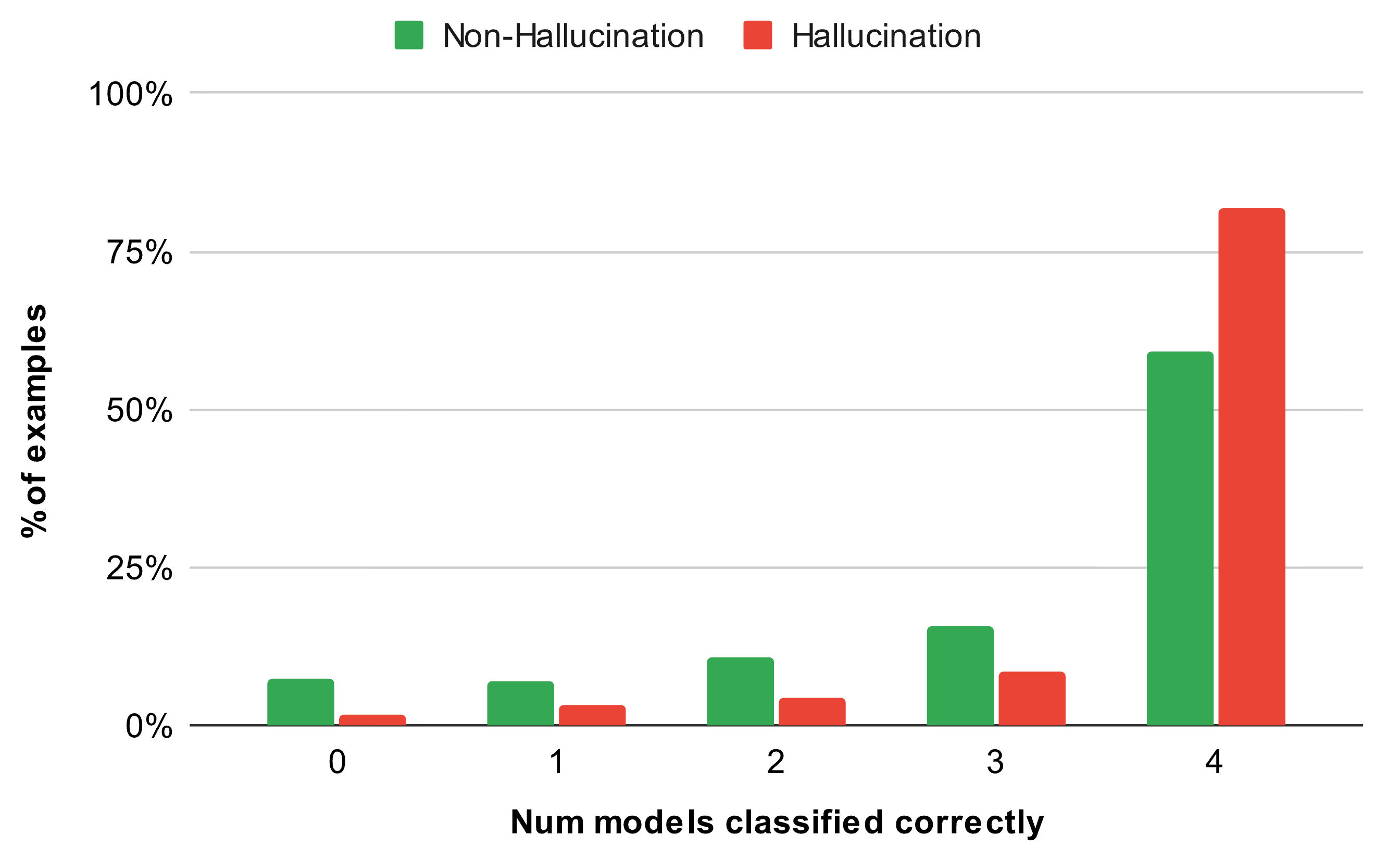
• Finding 3: An ensemble outperforms individual models. In many cases, the best performance is achieved by combining the assessments of multiple models. We developed an ensemble approach, where a hallucination is only flagged as such if two or more models agree on it. Our experiments showed that the majority vote-based classification significantly boosted the overall F1 score to 91.53%, surpassing the performance of each individual model. We also examined how models reached consensus when predicting hallucinations (⅔ of the examples) versus non-hallucinations (⅓ of the examples). As illustrated in the figure below, models were more likely to agree on hallucinations (95.1% of the time, with 2+ models in agreement) than on non-hallucinations (85.5% of the time). As a result, our ensemble’s recall (95.1%) was higher than its precision (88.2%).
Authors: Konstantinos Aisopos and Jeremy Greer
Contributors: Matthew Persons, Panos Achlioptas, and Michael Schuler