Run GRPO Training in Oumi Using the trl and verl Libraries
How to run Group Relative Policy Optimization in Oumi using trl and verl — simpler, cheaper RL training without a value model
By Stefan Webb
September 14, 2025
DeepSeek-R1 made a big splash earlier this year as an open-weight frontier model with powerful reasoning capabilities. However, what's even more impressive than the model's performance is its training process. The DeepSeek team pioneered using large-scale reinforcement learning with verifiable reward functions, greatly simplifying the training pipeline.
Part of DeepSeek's success was due to utilizing their newly developed Group Relative Policy Optimization (GRPO) algorithm. GRPO is a reinforcement learning algorithm introduced in the DeepSeekMath paper, with applications including preference tuning and training reasoning models. In this blog post, we will provide a brief overview of reinforcement learning and GRPO, followed by a step-by-step guide on how to run GRPO training in Oumi using the Hugging Face trl library or the ByteDance verl library.
Background
Reinforcement learning (RL) has commonly been used to align large language models (LLMs) with human preferences (ex. being conversational, helpful, and harmless). This is known as Reinforcement Learning from Human Feedback (RLHF), where a reward model is trained with human preferences on model outputs. The reward model is then used to post-train the LLM with an RL algorithm such as Proximal Policy Optimization (PPO). RLHF was one of the primary reasons behind the success of ChatGPT, and has been a staple in most frontier LLM training pipelines.
Figure 1: An overview of the RLHF process.
PPO RLHF Challenges
While this process is successful in aligning LLMs with human preferences, it has some drawbacks.
First, PPO has high compute and memory requirements during the training process. Two models are trained in PPO: the policy model (the LLM being trained, also known as the actor) and the value model (the critic)*. In addition, two other frozen models are loaded in memory: the reward model and the reference model (an older snapshot of the policy model).
Second, using an LLM as the reward model has many difficulties:
The reward model must be trained separately before PPO training, and requires labeled human preference data.
This prerequisite step complicates the overall RLHF training process, and makes rapid experimentation difficult.
The reward model is only a proxy for human preferences, and issues with its quality can negatively affect the PPO training process.
The size of the reward model is often significantly smaller than the policy model, affecting its ability to learn from its training data.
As the policy model is trained in PPO, the reward model becomes stale, as it was trained on the outputs of an old policy.
GRPO
GRPO helps address this first drawback. GRPO is very similar to PPO, with the key benefit being that it does not require a value model. Instead, GRPO generates multiple outputs for each prompt and calculates a reward value for each, using the average reward as the baseline. GRPO calculates the advantage for an output by how much higher its reward value is compared to this baseline.
By removing the value model, the only model that needs to be trained in GRPO is the policy model. This significantly speeds up the training process, and reduces memory usage as well.
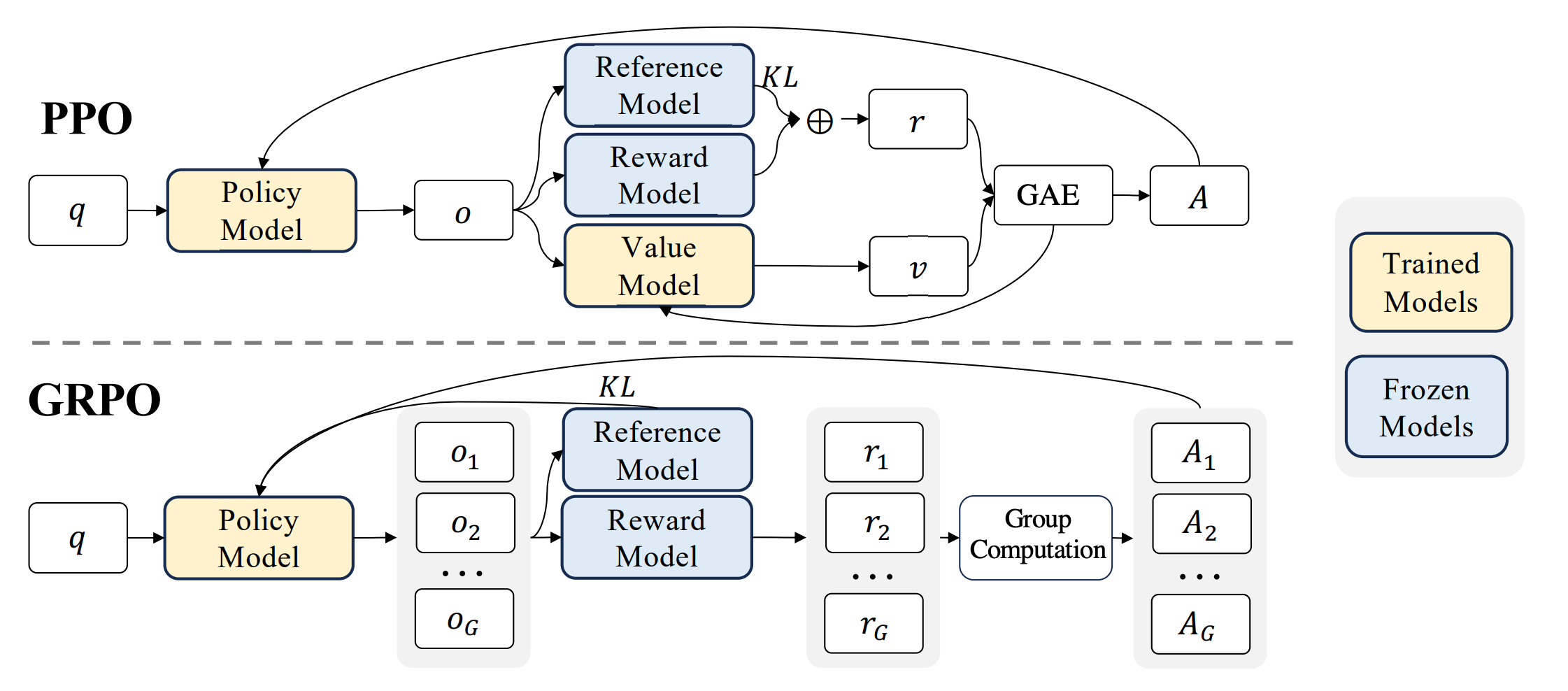
Figure 2: An overview of the difference between PPO and GRPO.
Verifiable Reward Functions
Another application of reinforcement learning is training reasoning models using rule-based reward functions. One of the major breakthroughs of DeepSeek-R1 was using large-scale reinforcement learning with GRPO and simple formatting/correctness reward functions to teach a model to reason. Unlike reward models, which try to model something complex like human preference, rule-based functions are best used when the task has easily verifiable results (correct answer, proper code syntax, etc.). Areas like math and coding are well-suited for this, while open-ended ones like creative writing are not.
This addresses both of the drawbacks mentioned above. First, the reward function replaces the reward model, reducing memory usage and computation required. Only two models are required for GRPO with rule-based reward functions: the policy model, and the reference model (a frozen copy of the policy model). Second, the rule-based reward function is much simpler than the reward model, simplifying the experimentation process and allowing users to directly craft the reward signal.
Running GRPO
While RL is an important step in training LLMs, it is more difficult to implement than supervised fine-tuning (SFT) since it involves multiple models, token generation, and a more complex training loop. However, many open-source RL frameworks are available, which support features such as vLLM for generation, scalability to multi-node training, and custom reward models/functions.
We are excited to announce that Oumi now supports GRPO training from two of these frameworks: trl by Hugging Face and verl by ByteDance! This allows you to run GRPO training with no/low code using Oumi's configs. You can also benefit from other features of the Oumi platform, such as custom evaluation and launching remote jobs.
Running GRPO training in Oumi is as simple as:
Create a reward function, and register it to Oumi's reward function registry using
@register("<my_reward_fn>", RegistryType.REWARD_FUNCTION).
Create a dataset class to process your HF dataset into the format needed for your target framework, and register it to Oumi's dataset registry using
@register_dataset("@hf-org-name/my-dataset-name").
Create an Oumi training config with your model, dataset, reward function, and hyperparameters. For specific details on setting up the config for GRPO, see our documentation.
Launch the training job locally using the oumi train CLI, or launch a remote job using the oumi launch CLI.
Below, we'll walk through the specifics of each framework.
trl Library
trl is a library by Hugging Face for training transformer models. It provides a GRPO trainer which is tightly integrated with the Hugging Face ecosystem. It has native support for Hugging Face models and datasets, and shares hyperparameters with the base Hugging Face trainer.
For an end-to-end example using Oumi + trl, check out our notebook walkthrough. It demonstrates how to train a model on the task of counting letters in words, so that LLMs can finally know how many r's are in "strawberry"!
verl Library
verl is a recently released RL library by ByteDance, with support for many algorithms including GRPO. Compared to trl, verl exposes much more hyperparameters (200+ total), and natively supports GRPO for vision-language models. However, it may be unfamiliar to those used to the HF trainers. It also requires additional work to integrate with HF datasets and models, but Oumi automatically takes care of this!
To see an example, check out our job config for running multi-modal GRPO on the Geometry3K dataset. This example uses one of verl's built-in reward functions, but you can easily change it to use your own!
Conclusion
In this blog post, we've done an overview of reinforcement learning, how GRPO with rule-based reward functions is an improvement over PPO, and how to run GRPO training with Oumi. Now, it's your turn! Try using GRPO to RLHF tune a model, teach a model to reason, or learn a task with a verifiable result. We're excited to see what you'll build with Oumi using these RL frameworks!
* Note that you can have the value model share layers with the policy model and use a separate head for value prediction, which can help reduce memory usage.
Authors: William Zeng, Nikolai Glushnev
Contributors: , Ben Feuer, Jeremy Greer, Oussama Elachqar