Introducing HallOumi: A State-of-the-Art Claim-Verification Model
An open-source 8B hallucination detection model that outperforms GPT-4 and Claude 3.5 with per-sentence verification and citations
By Stefan Webb
September 14, 2025
Today, we're excited to introduce HallOumi-8B and HallOumi-8B-Classifier, a family of open-source claim verification (hallucination detection) models, outperforming DeepSeek R1, OpenAI o1, Google Gemini 1.5 Pro, Llama 3.1 405B, and Claude Sonnet 3.5 at only 8 billion parameters!

Hallucinations
Hallucinations are frequently cited as one of the most critical challenges in deploying generative models across both commercial and personal applications, and for good reason:
Lawyers sanctioned for briefing where ChatGPT cited 6 fictitious cases
Air Canada required to honor refund policy made up by its AI support chatbot
Ultimately, it boils down to a matter of trust — generative models are trained to produce outputs which are probabilistically likely, but not necessarily true. While such tools are incredibly useful in the right hands, the inability to trust them hinders broader AI adoption, where they can be utilized safely and responsibly.
Building Trust in AI

To even begin trusting AI systems, we must be able to verify their outputs. By "verify", we specifically mean that we need to:
Assess the truthfulness of each statement produced by any model.
Identify the evidence that supports the validity of statements or reveals their inaccuracies.
Ensure full traceability by linking each statement to its supporting evidence.
If any of these crucial aspects are missing, the system cannot be verified and therefore cannot be trusted. However, this alone is not sufficient; we must also be capable of performing these tasks in a meticulous, efficient, and human-readable manner.
HallOumi, the hallucination detection model built on the Oumi platform, is specifically designed to enable per-sentence verification of any content (whether AI-generated or human-created) through sentence-level citations and human-readable explanations. For example, when provided with one or more context documents and an AI-generated response, HallOumi identifies and analyzes each claim in the response and determines the following:
The degree to which the claim is supported or unsupported by the provided context along with a confidence score. This score is critical for allowing users to define their own precision/recall tradeoffs when detecting hallucinations.
The citations (relevant sentences) associated with the claim, allowing humans to easily check only the relevant parts of the context document to confirm or refute a flagged hallucination, rather than needing to read through the entire document, which could be very long.
An explanation detailing why the claim is supported or unsupported. This helps to further boost human efficiency and accuracy, as hallucinations can often be subtle or nuanced.
Besides the generative HallOumi model, we are also open-sourcing a classification model. The classifier lacks the ergonomics of the generative HallOumi (per-sentence classification, citations, explanation), but is much more computationally efficient. It can be a better option when compute cost and latency is more important than human efficiency.
HallOumi has been trained with subtlety in mind — it has been fine-tuned to explicitly evaluate each statement within a given response as a claim. Additionally, it is designed to not make any assumptions when assessing the groundedness of each statement, as doing so could be highly problematic in mission-critical scenarios.
For more technical details about our approach, see below.
Disclaimer: HallOumi is an innovative, cutting-edge solution currently in active development. We welcome any feedback to help us refine and enhance it. Please reach out at contact@oumi.ai.
Evaluation
After thoroughly examining the majority of released open-source hallucination benchmarks, we found them to be unreliable for two key reasons. First, a significant portion of the examples are nonsensical because they are automatically extracted from larger documents without sufficient context. Second, numerous examples are mislabeled, either due to limitations of older-generation models or because human annotators overlooked subtle details that were crucial in determining whether a given instance was truly a hallucination.
To effectively evaluate HallOumi’s performance against existing solutions, we developed a benchmark that accurately reflects the problem-space. This benchmark includes:
Documents across a broad spectrum of topics with varying levels of information density
Requests corresponding to various types of summarization and QA tasks
AI-generated responses for these requests across the aforementioned documents
To facilitate this, we introduced and open-sourced the Oumi Groundedness Benchmark. This benchmark consists of 2089 prompts, each containing a context document, a response, and a label. The labels were generated using Llama 405B with a single-shot prompt example and human-in-the-loop. To validate their accuracy, we sampled 760 claims, had them annotated by a linguistic expert, and ensured a high level of agreement with the benchmark labels (94.5%).
The table below presents our evaluation of HallOumi compared to leading models, as measured on the Oumi Groundedness Benchmark. Results display both Macro F1 scores and Balanced Accuracy, with mean values and standard deviations to indicate statistical reliability.
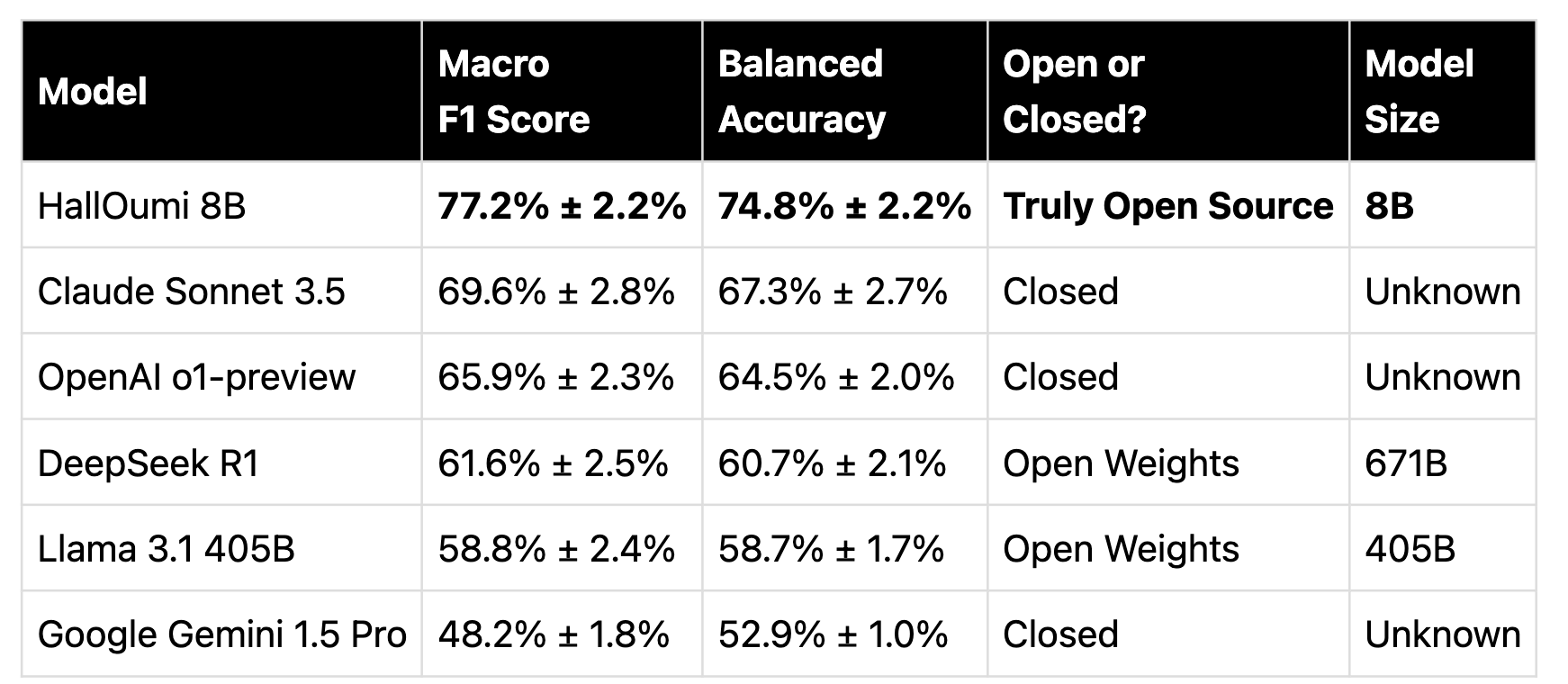
To learn more about our evaluation process, please refer to our notebook.
Open-Sourcing HallOumi
The HallOumi family of models was trained using Oumi, with a set of datasets synthesized and curated using the Oumi platform.
The HallOumi family of models is available on Hugging Face:
Generative HallOumi: https://huggingface.co/oumi-ai/HallOumi-8B
Classifier HallOumi: https://huggingface.co/oumi-ai/HallOumi-8B-classifier
The datasets used to train HallOumi are also available on Hugging Face:
Oumi Synthetic Claims
Oumi Synthetic Document Claims
Oumi ANLI Training Subset
Oumi MiniCheck C2D & D2C Training Set
To train HallOumi yourself, see our recipe on GitHub.
To learn more about the Oumi platform, see our GitHub page.
Authors: Jeremy Greer, Manos Koukoumidis, Konstantinos Aisopos, and Michael Schuler
Contributors: Matthew Persons, Panos Achlioptas, William Zeng, and Oussama Elachqar